Principles for Data and Analytical Workflows
A data or analytical workflow does not exist in a vacuum. It is read by colleagues, rerun by collaborators, extended by future versions of yourself, and scrutinized by stakeholders who need to trust its outputs. For all of this to work well, a workflow needs to be built on solid foundations, not just technically correct, but designed with care. The principles laid out here are organized around three core ideas: Reproducibility, Maintainability, and Optimality. Each of these breaks down into a set of sub-principles that together define what it means to work with rigor and intentionality.
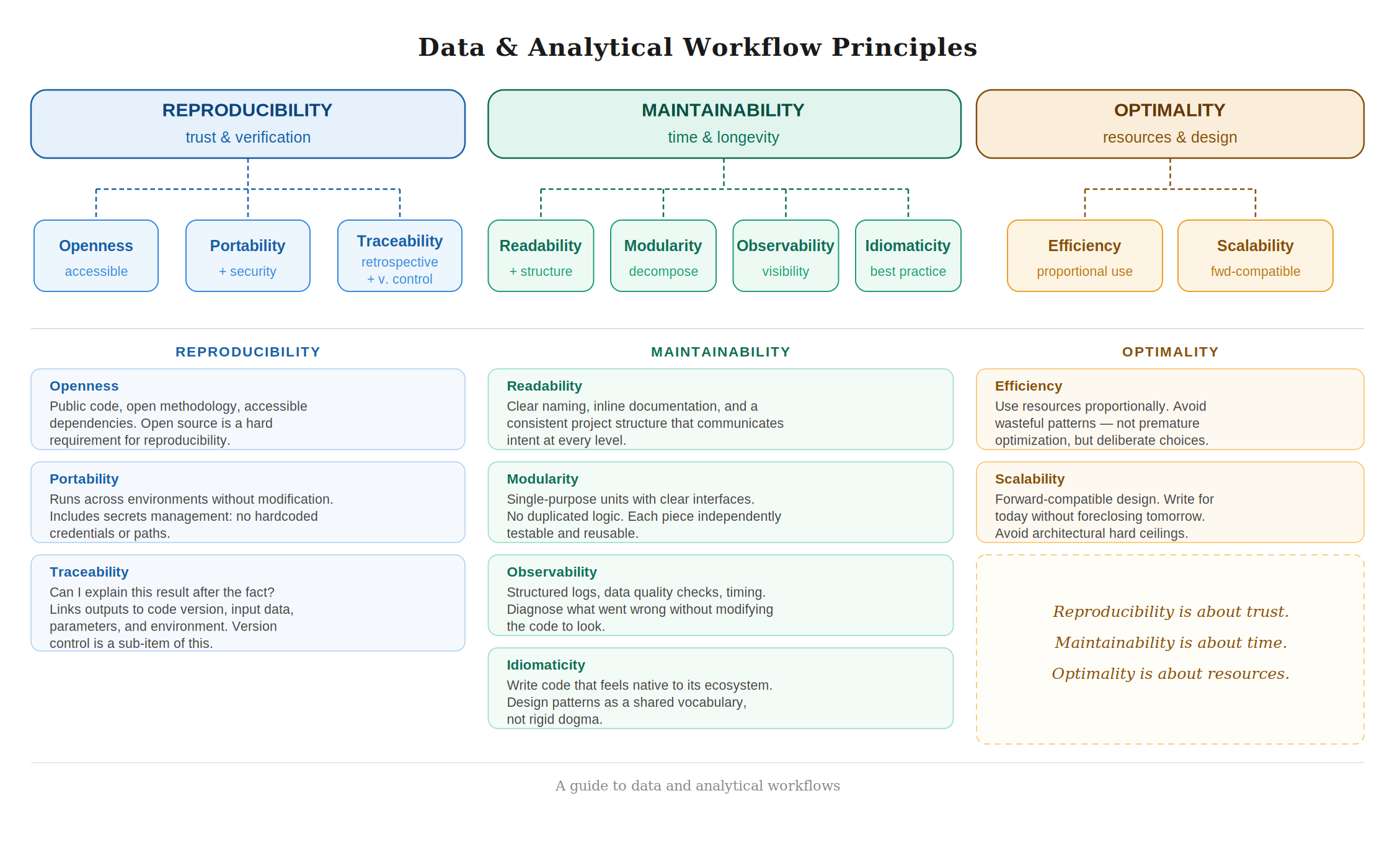
1. Reproducibility
A reproducible workflow is one that can be independently verified. Given the same inputs, the same code, and the same environment, it should always produce the same outputs, by a colleague, by a reviewer, or by your future self six months from now. But reproducibility is not just a technical property; it is a commitment to transparency and accountability. It requires that the workflow be open and accessible, that its history be traceable, and that changes to it be controlled and deliberate.
1.1 Openness
Reproducibility without openness is a contradiction. A workflow that lives in a private repository, depends on proprietary tools, or requires institutional access that others do not have is not truly reproducible. It is just internally consistent. As a principle, openness means making code, data (where possible), and methodology publicly accessible. It is the foundation on which all other reproducibility guarantees rest. To borrow a phrase from Bruno Rodrigues in his book Building reproducible analytical pipelines with R that captures this well: open source is a hard requirement for reproducibility. This does not mean every project must be public from day one, but it does mean that the default posture should be toward openness, and that reproducibility claims cannot be fully honored without it.
1.2 Portability
A workflow is portable when it runs correctly across different environments (your laptop, a colleague's machine, or a cloud server) without requiring manual adjustments. This means declaring dependencies explicitly, isolating environments (through tools like virtual environments, containers, or lockfiles), and avoiding hardcoded paths or platform-specific assumptions. Portability also encompasses security: secrets, API keys, and credentials should never be embedded in code or version-controlled files. They belong in environment variables or dedicated secret management tools. A workflow that leaks credentials is not just a security risk, it is a portability failure, because it might break the moment someone else tries to run it safely.
1.3 Traceability
Traceability is the retrospective view of reproducibility. Where reproducibility asks "can I re-run this and get the same result?", traceability asks "can I explain this result after the fact?". A traceable workflow makes it possible to look at any output and answer: which version of the code produced it, which input data was used, which parameters were set, and in what environment it ran. This is not just useful for debugging, it is essential for accountability in collaborative or regulated settings. Think of traceability as the audit trail that sits behind reproducibility: one faces forward, the other looks back, and together they close the loop.
If traceability is about reading the history of a result, version control is about writing that history in the first place. It is the mechanism that makes traceability possible on the code side, without a versioned codebase, you cannot reliably answer which code produced a given output, no matter how carefully you log everything else. However, versioning is not only intended to keep a track of your codebase, it is also intended to keep a track of how your data and outputs change.
2. Maintainability
A maintainable workflow is one that ages well. Code will be read far more times than it is written, and a workflow that cannot be understood, extended, or debugged without heroic effort is a liability. Maintainability is not about following rules for their own sake, it is about respecting the time and cognitive load of every person who will touch the code after it is first written, including yourself. It is achieved through clarity, structure, good decomposition, and idiomatic practice.
2.1 Readability
Readability is the most immediate form of maintainability. Code is readable when its intent is clear without requiring the reader to reconstruct the author's thought process. This means choosing meaningful and consistent names for variables, functions, and files; commenting where logic is non-obvious; keeping and updating documentation; and keeping individual units of code focused and short enough to reason about at a glance. Readability also extends to having a clear, in-depth and updated documentation (notes, data dictionaries, methodology, metadata, codebooks, a README file). Finally, a well-organized directory structure is important to communicate the shape of a project before a single line of code is read. Folders should have clear, consistent names; raw data should be separated from processed data; scripts should be separated from notebooks; configuration should be separated from logic. A messy file system is the equivalent of messy code: it makes everything harder.
2.2 Modularity
Modularity is the structural discipline that makes readability and maintainability sustainable as a project grows. A modular workflow decomposes logic into discrete, single-purpose units (functions, scripts, or modules) each with a clear interface and minimal side effects. No single function should try to do too much. No piece of logic should be duplicated across multiple places. Modules should be independently testable and reusable in different contexts. If readability is about making individual lines and blocks of code clear, modularity is about making the architecture of the whole workflow comprehensible. The two reinforce each other: modular code tends to be more readable, and readable code is easier to modularize well.
2.3 Observability
A workflow is observable when you can understand what it is doing, and what went wrong, without modifying the code to investigate. This means emitting structured logs at meaningful points in the pipeline, asserting expectations about data at key stages (checking schemas, ranges, nulls, row counts), and surfacing timing and resource information where relevant. Observability is not the same as debugging; it is the practice of building visibility into the workflow from the start, so that when something breaks in production or in a scheduled run, the evidence is already there. Think of it as the difference between a black box and a glass box, the code runs the same either way, but one lets you see inside.
2.4 Idiomaticity
Every programming language has a culture: conventions, patterns, and idioms that experienced practitioners have converged on because they work well in that language's ecosystem. Idiomatic code is code that feels native. It uses the language's strengths deliberately, follows its community conventions, and avoids patterns that are technically valid but foreign to the ecosystem. In R, this might mean embracing vectorization and the tidyverse grammar where appropriate. In Python, it might mean using list comprehensions, context managers, and following PEP 8. Beyond syntax, idiomaticity also means being familiar with design patterns, not as dogma, but as a shared vocabulary for solving common structural problems. Code that fights against its language is harder to read, harder to maintain, and harder for collaborators to contribute to.
3. Optimality
An optimal workflow is one where resources (time, memory, compute, and human effort) are used appropriately for the task. This does not mean chasing performance for its own sake. Premature optimization is a well-known trap, and a workflow that is fast but unreadable is not optimal in any meaningful sense. Optimality is about making deliberate choices: choosing the right tool, avoiding wasteful patterns, and designing with the future in mind.
3.1 Efficiency
An efficient workflow uses computational resources appropriately for the problem at hand. This means being aware of the cost of operations (in time, memory, and money) and avoiding patterns that waste them needlessly: reading the same file multiple times when it could be cached, running sequential operations that could be parallelized, or loading entire datasets into memory when only a subset is needed. Efficiency is not about writing the fastest possible code; it is about not being careless. The standard is proportionality: the resources consumed should be commensurate with what the problem actually requires.
3.2 Scalability
Scalability is efficiency extended into the future. A scalable workflow is one that handles growth (in data volume, in the number of users, in analytical complexity) without requiring a fundamental redesign. But more than that, scalability is a design philosophy: write for the problem you have today in a way that does not foreclose the solutions you will need tomorrow. This means avoiding design decisions that create hard ceilings: tightly coupled components, hardcoded assumptions about data size, or logic that only works for a specific schema. It does not mean over-engineering upfront or anticipating every possible future requirement. It means asking, when making structural decisions: if the data doubles, or a follow-up question comes in six months, will this still hold? A workflow that answers that question honestly, and designs accordingly, is a scalable one.
These three principles are, in the end, expressions of different kinds of respect. Reproducibility is about trust: others, regulators, or your future self can verify your work. Maintainability is about time: the workflow remains workable as it ages. Optimality is about resources: the workflow is worth running.